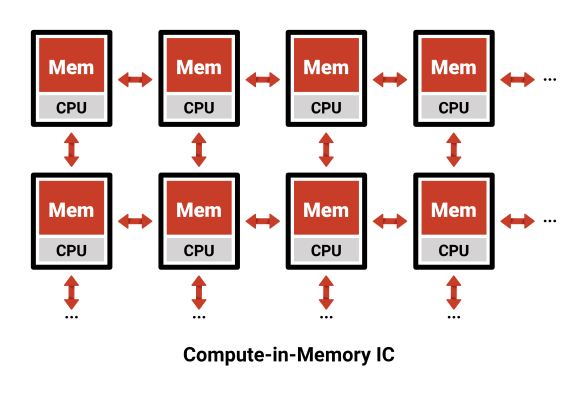
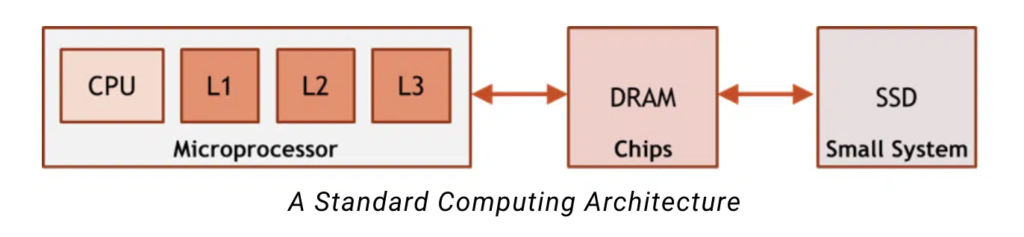
Вычисления в памяти строятся с использованием разных предположений: у нас есть большой объем данных, к которым нам нужно получить доступ , но мы точно знаем, когда они нам понадобятся. Эти предположения возможны для приложений вывода ИИ, потому что поток выполнения нейронной сети детерминирован — он не зависит от входных данных, как многие другие приложения. Используя это знание, мы можем стратегически контролировать расположение данных в памяти, вместо того чтобы строить иерархию кеша, чтобы компенсировать недостаток знаний. Вычисления в памяти также добавляют локальные вычисления к каждому массиву памяти, что позволяет обрабатывать данные непосредственно рядом с каждой памятью . Имея вычисление рядом с каждым массивом памяти, мы можем иметь огромную память, которая имеет ту же производительность и эффективность, что и кэш L1 (или даже регистровые файлы).