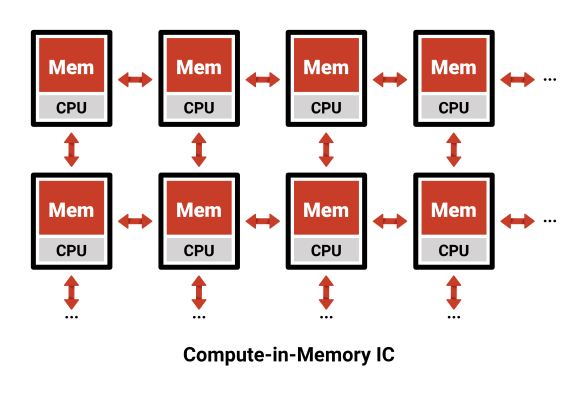
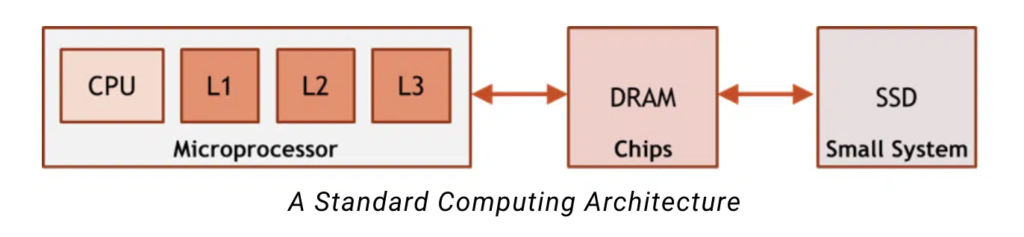
Today’s most common computing architectures are built on assumptions about how memory is accessed and used. These systems assume that the full memory space is too large to fit on-chip near the processor, and that we do not know what memory will be needed at what time. To address the space issue and the uncertainty issue, these architectures build a hierarchy of memory. The memory hierarchy near the CPU is small and fast and can support high frequency of use, while DRAM and SSD are large enough to store the bulkier, less time-sensitive data.