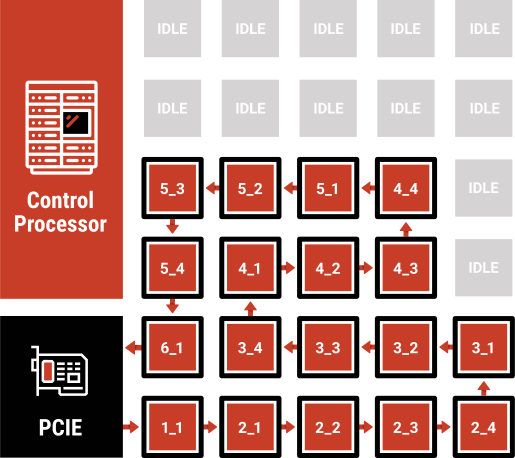
Dataflow Architecture Maximizing inference performance through careful architecture design
Standard compute architectures are designed to tackle sequential algorithms. They excel at these algorithms by using a massively powerful and power-intensive CPU core, surrounding it with a memory architecture that matches the memory profile of those applications. AI inference is not a typical sequential application; it is a graph-based application where the output of one graph node flows to the input of other graph nodes.
Graph applications provide opportunities to extract parallelism by assigning a different compute element to each node of the graph. When the results from one graph node are completed, they flow to the next graph node to start the next operation, which is ideal for dataflow architecture. In our dataflow architecture, we assign a graph node to each compute-in-memory array and put the weight data for that graph node into that memory array. When the input data for that graph node is ready, it flows to the correct location, adjacent to the memory array, and then is executed upon by the local compute and memory. Many inference applications use operations like convolution, which processes bits of the image frame instead of the whole frame at once.
Our dataflow architecture also maximizes inference performance by having many of the compute-in-memory elements operating in parallel, pipelining the image processing by processing neural networks nodes (or “layers”) in parallel in different parts of the frame. By being built from the ground up as a dataflow architecture, the AiVolga architecture minimizes the memory and computational overhead required to manage the dependency graphs needed for dataflow computing, and keeps the application operating at maximum performance.